
La recherche vectorielle est une méthode pour trouver des entités similaires (phrases, images, vidéos) en utilisant des représentations mathématiques de ces entités. Ces représentations sont appelées des embeddings qui sont exprimées sous forme de vecteurs et qui sont par la suite utilisés pour effectuer la recherche vectorielle.
Pour en savoir plus, consultez notre wiki sur les bases de la recherche vectorielle.
 Qu’est ce que c’est la recherche vectorielle ?
Qu’est ce que c’est la recherche vectorielle ?
Qu’est ce que c’est la recherche vectorielle ? L’introduction de la recherche vectorielle dans BigQuery
En Janvier 2024, Google a annoncé l’intégration de la recherche vectorielle dans BigQuery en preview à travers la fonction
VECTOR_SEARCH, et la fonction CREATE VECTOR INDEX qui permet de créer des indices pour améliorer la recherche et le calcul de distance entre les vecteurs.La recherche vectorielle dans BigQuery nécessite une base de données contenant des "embeddings" afin de calculer les distances entre les éléments et d'évaluer leur similitude.
Il y a plusieurs moyens pour créer des embeddings, cependant, on se focalisera sur la fonctionnalité intégrée de BigQuery pour le faire :
ML.GENERATE_EMBEDDING.La fonction
ML.GENERATE_EMBEDDING permet de générer directement dans BigQuery des embeddings en utilisant un modèle de VERTEX AI.Guide d’utilisation :
Dans notre guide détaillé, nous allons utiliser la recherche vectorielle sur BigQuery pour trouver des titres d’articles similaires dans une base de données de bbc_news qui est disponible pour le public sur le dataset
bigquery-public-data.
L’objectif de cet exercice est de trouver les articles qui ont un titre similaire à un titre d’article qui nous intéresse dans la base de données. 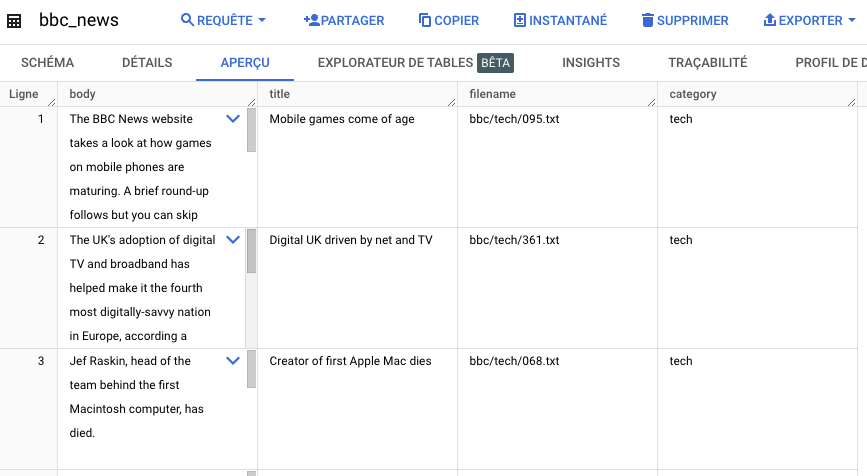
La génération des embeddings :
Comme mentionné précédemment, pour effectuer une recherche vectorielle, il est nécessaire d'utiliser des embeddings.
Pour en créer, nous vous détaillons les étapes à suivre :
La création d’un ensemble de données sur BigQuery
Il s'agit de créer un nouveau dataset sur BigQuery pour stocker le modèle que nous utiliserons pour générer les embeddings, ainsi que les différentes tables que nous créerons par la suite.
Pour en faire, il suffit d’exécuter la requête suivante :
sqlCREATE SCHEMA `toolbox-starfox.vector_search_demo`
Pour en savoir plus rendez-vous sur la documentation de BigQuery.
La création d’une connexion des ressources Cloud.
Pour pouvoir créer une connexion BigQuery avec les ressources Cloud, il faut :
- Activer l’API : BigQuery Connection API.
- Avoir les rôles de :
-
roles/bigquery.connectionAdmin resourcemanager.projects.setIamPolicyroles/bigquery.dataEditorroles/bigquery.user
- Créer la connexion avec le modèle de Vertex AI dans BigQuery :
- Attribuer le rôle
Utilisateur VERTEX AIau compte de service de la connexion :
La création du modèle pour la génération des embeddings :
Pour créer le modèle, il suffit d'exécuter cette simple requête :
sqlCREATE OR REPLACE MODEL `vector_search_demo.embeddings_model_demo` REMOTE WITH CONNECTION `projects/toolbox-starfox/locations/us/connections/embeddings-test` OPTIONS (ENDPOINT = 'text-embedding-004');
Il existe plusieurs modèles sur Vertex AI pour générer des embeddings, pour utiliser le modèle multilangue, on utilise
textembedding-gecko-multilingual@001 ou text-multilingual-embedding-002.
👉 Pour plus de détails, rendez-vous sur la documentation de Google.N’oubliez de remplacer le dataset par le nom de votre
dataset. et de donner un nom à votre modèle.
LOCATION, et CONNECTION.ID que vous pouvez trouver dans le détail des informations de connexion.
La génération des embeddings :
Pour générer les embeddings nécessaires pour appliquer la recherche vectorielle, il suffit d’exécuter cette requête, dans notre exemple, on va générer les embeddings de “title” depuis la table bbc_news.
sqlCREATE OR REPLACE TABLE `toolbox-starfox.vector_search_demo.bbc_news_embeddings` AS ( SELECT * FROM ML.GENERATE_EMBEDDING( MODEL `toolbox-starfox.vector_search_demo.embeddings_model_demo`, (select title as content from `toolbox-starfox.vector_search_demo.bbc_news`), STRUCT(TRUE AS flatten_json_output, 'SEMANTIC_SIMILARITY' as task_type) ));
👉Pour plus de détails sur les options de cette requête consultez la documentation de Google.
La génération de l’indice de la recherche vectorielle
Un indice vectoriel est une structure de données spécialisée qui optimise la fonction
VECTOR_SEARCH pour une recherche plus rapide parmi les embeddings. Son principe repose sur la technique ANN (Approximate Nearest Neighbor, ou "recherche approximative des plus proches voisins").La méthode IVF est une approche spécifique pour créer un indice vectoriel. Voici comment elle fonctionne :
- Clustering avec k-means :
- Les données vectorielles sont d'abord regroupées en clusters à l'aide de l'algorithme k-means.
- Chaque cluster représente un groupe de vecteurs similaires.
- Partitionnement :
- Les données vectorielles sont ensuite organisées en fonction de ces clusters.
- Cela crée une structure "inversée" où chaque cluster pointe vers les vecteurs qu'il contient.
- Recherche optimisée :
- Lors d'une recherche avec
VECTOR_SEARCH, l'algorithme peut rapidement identifier les clusters pertinents. - La recherche se concentre ensuite sur ces clusters spécifiques, réduisant considérablement l'espace de recherche.
Cette commande crée un indice vectoriel sur la colonne spécifiée, en utilisant la méthode IVF et la distance cosinus pour mesurer la similarité entre les vecteurs.
sqlCREATE OR REPLACE VECTOR INDEX my_index_bbc ON `toolbox-starfox.vector_search_demo.bbc_news_embeddings`(ml_generate_embedding_result) OPTIONS(index_type = 'IVF', distance_type = 'COSINE')
- Tous les éléments du tableau (array) des embeddings doivent être non-
NULL, et toutes les valeurs de la colonne doivent avoir les mêmes dimensions de tableau. Il est donc obligatoire de nettoyer votre nouvelle table qui contient les embeddings (dans notre cas : bbc_news_embeddings) en supprimant les NULL dans la colonneml_generate_embedding_result.
- Il faut que la table contienne au minimum 5000 pour la requête CREATE VECTOR INDEX avec le type d'index IVF. Dans le cas échéant on peut passer cette étape.
👉Pour plus de détails sur les options de cette requête consultez la documentation de Google.
L’utilisation de la recherche vectorielle
La dernière étape consiste à utiliser la recherche vectorielle pour trouver des titres similaires à un titre dans la table, le rôle de cette requête est d’utiliser la table qu’on a créée auparavant qui contient les embeddings, pour chercher les titres ayant des embeddings proches de ceux de titre qu’on essaye d’analyser et qui est dans notre exemple : “PlayStation 3 chip to be unveiled” en utilisant la méthode de calcul de distance : COSINE.
sqlSELECT query.title,base.content FROM VECTOR_SEARCH (TABLE `toolbox-starfox.vector_search_demo.bbc_news_embeddings`, 'ml_generate_embedding_result', (SELECT ml_generate_embedding_result, content as title FROM ML.GENERATE_EMBEDDING( MODEL `toolbox-starfox.vector_search_demo.embeddings_model_demo`, (Select "PlayStation 3 chip to be unveiled" AS content), STRUCT (TRUE AS flatten_json_output))), distance_type => 'COSINE') );
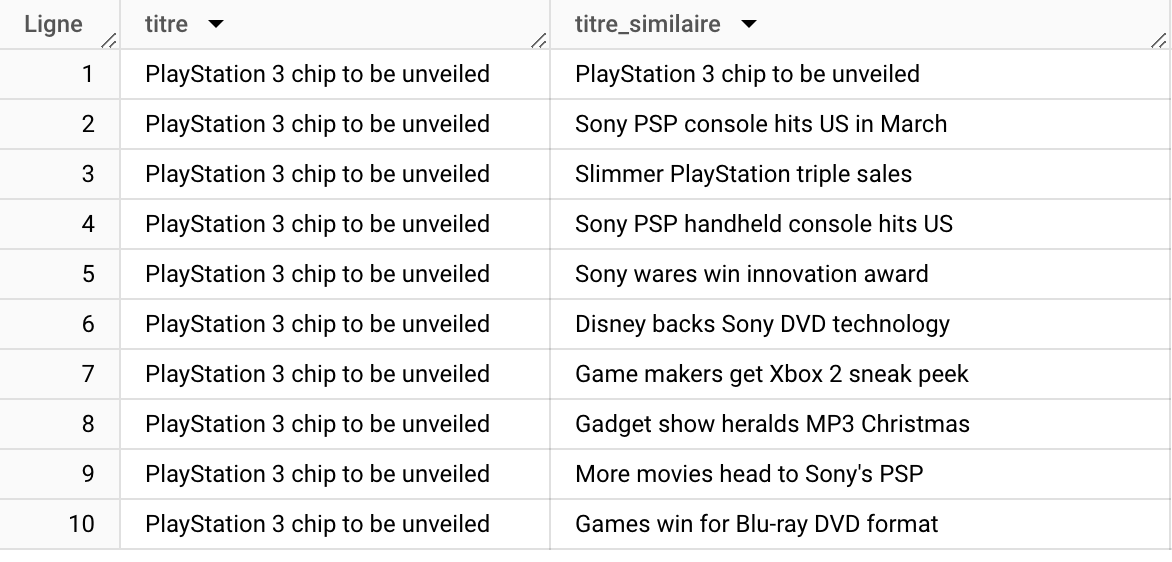
Le résultat est significatif, on voit que Sony PSP, XboX 2 et Sony sont identifiés comme des mots sémantiquement similaires à PlayStation, ce qui veut dire que la recherche vectorielle a bien fonctionné, évidemment on peut toujours améliorer le résultat en optimisant les options du modèle 👇.
Vous pouvez utiliser
num_lists avec l'argument fractions_list_to_search de la fonction VECTOR_SEARCH pour optimiser la recherche vectorielle.- Si vos données sont réparties en nombreux petits groupes dans l'espace vectoriel :
- Utilisez une valeur élevée pour
num_lists - Utilisez une valeur basse pour
fractions_list_to_search
- Si vos données sont réparties en peu de grands groupes :
- Utilisez une valeur basse pour
num_lists - Utilisez une valeur élevée pour
fractions_list_to_search
Si vous ne spécifiez pas de valeur pour
num_lists, BigQuery en calculera une automatiquement.L'intégration de la recherche vectorielle dans BigQuery constitue une avancée notable pour les entreprises. Cette fonctionnalité est particulièrement avantageuse pour les PME, leur permettant d'accéder à des capacités d'analyse avancées. Elle ne se limite pas à une simple amélioration technique ; elle représente un véritable levier de transformation pour les entreprises, leur permettant d'exploiter pleinement le potentiel de leurs données dans un monde de plus en plus numérique et compétitif.